

Top 60 GCP Data Engineer Interview Questions and Answers (2026)
Navigate through this article using the table of contents below
Table of Contents
No headings found in this article.
Landing a GCP Data Engineer role is not just about knowing the tools — it is about proving you can use them. Interviews test your hands-on knowledge of BigQuery, Dataflow, Pub/Sub, and Cloud Storage. Expect questions on building data pipelines, handling ETL processes, and solving real data problems using Google Cloud services clearly and confidently.
Most candidates fail not because of missing theory but due to lack of practical experience. This is exactly why quality GCP data engineer online training in India now emphasizes hands-on projects over slide-based learning. Interviewers ask how you load data into BigQuery, handle pipeline errors, or process real-time data using Pub/Sub. Having real project experience gives you a strong edge, as interviewers always prefer candidates who can explain what they built and how it actually worked.
GCP Data Engineer Core Concept Interview Questions You Must Know
Q1. What is BigQuery and how does it differ from a traditional relational database?
BigQuery is a fully managed, serverless data warehouse on Google Cloud designed for large-scale analytics. Unlike traditional relational databases like MySQL or PostgreSQL, BigQuery uses columnar storage and distributed computing, making it optimized for analytical queries over massive datasets rather than transactional operations. It scales automatically and charges based on data scanned, not server uptime.
Q2. What is the difference between Dataflow and Dataproc in GCP?
Dataflow is a fully managed, serverless service built on Apache Beam for both batch and streaming data processing. Dataproc is a managed Hadoop and Spark cluster service used for big data processing workloads. Use Dataflow when you want a serverless, auto-scaling pipeline with no cluster management. Use Dataproc when you have existing Spark or Hadoop jobs you want to migrate to the cloud with more control over the cluster environment.
Q3. What is Pub/Sub in GCP and when would you use it?
Pub/Sub is a fully managed real-time messaging service that decouples data producers from consumers. It follows a publish-subscribe model where producers send messages to a topic and consumers receive them via subscriptions. You would use Pub/Sub when building event-driven architectures, ingesting streaming data from IoT devices, application logs, or user activity events that need to be processed in real time.
Q4. What are the different types of tables in BigQuery?
BigQuery supports several table types. Native tables store data directly in BigQuery's columnar storage. External tables query data stored outside BigQuery, such as in Cloud Storage, without loading it. Partitioned tables divide data by date, timestamp, or integer range to improve query performance and reduce costs. Clustered tables organize data based on the values of specific columns, further optimizing query efficiency when filtering on those columns.
Q5. What is the difference between partitioning and clustering in BigQuery?
Partitioning divides a table into segments based on a date, timestamp, or integer column, allowing BigQuery to scan only the relevant partition during a query. Clustering organizes data within each partition based on the values of up to four columns. Partitioning reduces the amount of data scanned at a high level, while clustering fine-tunes performance within partitions. Using both together gives the best query performance and cost optimization for large datasets.
Q6. What is Apache Beam and how does it relate to Dataflow?
Apache Beam is an open-source unified programming model for defining both batch and streaming data processing pipelines. Dataflow is Google Cloud's fully managed execution engine that runs Apache Beam pipelines. In simple terms, you write your pipeline logic using Apache Beam SDK in Python or Java, and Dataflow handles the execution, scaling, and infrastructure management on GCP. Beam provides portability — the same pipeline can also run on Spark or Flink if needed.
Q7. What is Cloud Storage and what data formats does it support?
Cloud Storage is GCP's scalable object storage service used to store any type of unstructured data. It supports all common data formats including CSV, JSON, Avro, Parquet, ORC, and plain text files. In data engineering workflows, Cloud Storage typically acts as a staging layer where raw data lands before being processed and loaded into BigQuery or other services. It offers different storage classes — Standard, Nearline, Coldline, and Archive — based on access frequency and cost requirements.
Q8. What is the role of Cloud Composer in GCP Data Engineering?
Cloud Composer is a fully managed workflow orchestration service built on Apache Airflow. In data engineering, it is used to schedule, monitor, and manage complex data pipelines that involve multiple GCP services. For example, you can use Cloud Composer to trigger a Dataflow job after a file lands in Cloud Storage, then load the processed data into BigQuery, and send a notification upon completion. It provides a visual DAG-based interface to track pipeline execution and handle dependencies between tasks.
Q9. What is the difference between batch processing and stream processing in GCP?
Batch processing handles large volumes of data collected over a period of time and processes it all at once. In GCP, Dataflow and Dataproc are commonly used for batch workloads. Stream processing handles data continuously as it arrives in real time. In GCP, Pub/Sub combined with Dataflow is the standard architecture for streaming pipelines. The choice depends on business requirements — use batch when slight delays are acceptable and streaming when real-time insights are critical.
Q10. What is a PCollection in Apache Beam?
A PCollection is the core data abstraction in Apache Beam. It represents a distributed dataset that your pipeline works on, similar to how a DataFrame works in pandas but designed for distributed processing. A PCollection can be bounded, meaning it has a finite size like a batch file, or unbounded, meaning it is a continuous stream of data. Every transformation in a Beam pipeline takes one or more PCollections as input and produces a new PCollection as output.
Q11. How does BigQuery handle data ingestion?
BigQuery supports multiple ingestion methods. Batch loading allows you to load data from Cloud Storage in formats like CSV, JSON, Avro, and Parquet using load jobs. Streaming insertion allows you to push individual records in real time using the BigQuery Storage Write API or the older streaming inserts method. Data Transfer Service automates scheduled data loads from sources like Google Ads or external databases. Each method has different cost implications and latency trade-offs depending on your use case.
Q12. What is Dataproc and when should you use it over Dataflow?
Dataproc is a managed service for running Apache Spark and Hadoop workloads on GCP. You should choose Dataproc over Dataflow when you have existing Spark or Hadoop codebases that you want to migrate to the cloud without rewriting them in Apache Beam. Dataproc gives you more control over the cluster configuration, supports a wider range of Spark libraries, and is often more cost-effective for heavy Spark workloads. Dataflow is better suited when you want fully serverless, auto-scaling pipelines without managing cluster infrastructure.
Q13. What are the storage classes available in Cloud Storage and how do you choose between them?
Cloud Storage offers four storage classes. Standard is for frequently accessed data with no minimum storage duration. Nearline is for data accessed roughly once a month, such as backups. Coldline is for data accessed at most once a quarter, such as disaster recovery files. Archive is the lowest cost option for data accessed less than once a year. The choice depends on how frequently data needs to be retrieved, with retrieval costs increasing as storage costs decrease across the classes.
Q14. What is the BigQuery Storage Read API and why is it important?
The BigQuery Storage Read API allows high-throughput parallel reading of BigQuery table data directly into processing frameworks like Apache Spark, Beam, or TensorFlow without going through slow export jobs. It is important because it significantly reduces the time needed to move large datasets from BigQuery into external compute environments for machine learning or advanced analytics workloads. It supports column and row filtering, which means only the required data is transferred, reducing both cost and processing time.
Q15. What is the difference between a dataset, table, and view in BigQuery?
In BigQuery, a dataset is a container that organizes and controls access to tables and views, similar to a schema in a traditional database. A table stores actual data in rows and columns using BigQuery's columnar storage format. A view is a saved SQL query that acts like a virtual table — it does not store data itself but retrieves it dynamically when queried. Views are useful for simplifying complex queries, enforcing consistent logic across teams, and restricting access to specific columns or rows of underlying tables.
Read more about :- GCP Data Engineer Training in Bangalore
Scenario-Based GCP Data Engineer Interview Questions and How to Answer Them
Q1. Your Dataflow pipeline is receiving late-arriving data. How would you handle it?
Use windowing and triggers in Apache Beam. Apply allowed lateness to accept late records and use accumulation mode to update results. This ensures late data is processed without rerunning the entire pipeline, keeping your output accurate and reliable.
Q2. Your BigQuery query is scanning too much data and costs are rising. What would you do?
First, check if the table is partitioned and clustered. Rewrite the query to filter on partition columns, avoiding SELECT *. Use the query validator to check bytes scanned before running. These steps significantly reduce both cost and query execution time.
Q3. A file lands in Cloud Storage every hour and needs to be loaded into BigQuery automatically. How would you design this?
Use Cloud Storage trigger with Eventarc or a Cloud Function to detect new files. Trigger a Dataflow job or BigQuery load job automatically. This creates a fully automated, event-driven ingestion pipeline without any manual intervention.
Q4. Your Pub/Sub topic is receiving millions of messages per second. How do you ensure no data is lost?
Enable message retention on the Pub/Sub topic and use acknowledged delivery. Connect it to a Dataflow streaming pipeline with checkpointing enabled. If the consumer falls behind, retained messages ensure no data is dropped during high-traffic periods.
Q5. You need to process both historical and real-time data using the same pipeline logic. How would you approach this?
Use Apache Beam's unified model which handles both batch and streaming with the same code. Run historical data as a bounded PCollection and real-time data as unbounded through Pub/Sub. Deploy both on Dataflow for consistent, scalable execution.
Q6. Your BigQuery table has billions of rows and queries are getting slow. How would you optimize it?
Apply date-based partitioning and cluster on frequently filtered columns. Avoid querying unnecessary columns by selecting only what is needed. For repeated aggregations, use materialized views to cache results and reduce full table scans on every query run.
Q7. A Dataflow job is failing midway through processing. How would you troubleshoot it?
Check Dataflow job logs in Cloud Logging for specific error messages. Identify whether the failure is in a specific PTransform or data issue. Enable retry logic and test the pipeline locally using Direct Runner before redeploying to isolate the root cause quickly.
Q8. You need to migrate an on-premise SQL Server database to BigQuery. How would you plan this?
Use Database Migration Service or extract data as CSV or Parquet to Cloud Storage first. Then load into BigQuery using a load job. Validate row counts and data types post-migration. For ongoing sync, use Datastream for change data capture from the source database.
Q9. Your stakeholders need a dashboard that reflects data updated every 15 minutes. How would you build this pipeline?
Ingest data through Pub/Sub into a Dataflow streaming pipeline. Write processed results into BigQuery. Connect Looker Studio to BigQuery with a 15-minute scheduled refresh. This ensures stakeholders always see near-real-time data without building a complex custom solution.
Q10. You are asked to build a pipeline that processes clickstream data from a website in real time. How would you design it?
Capture events using a tracking script and push to Pub/Sub. Use Dataflow to parse, clean, and enrich the events. Store results in BigQuery partitioned by date. This architecture handles high-volume clickstream data reliably with minimal latency end to end.
Q11. A downstream team reports that data in BigQuery is duplicated. How would you investigate and fix it?
Check the ingestion method — streaming inserts can cause duplicates. Use INSERT with deduplication logic or switch to BigQuery Storage Write API with exactly-once semantics. Also check if the load job ran multiple times due to a retry without deduplication handling.
Q12. You need to join a 10TB table with a 500MB lookup table in BigQuery efficiently. How would you do it?
Use a broadcast join by placing the smaller table on the right side of the JOIN. BigQuery automatically applies broadcast join optimization for smaller tables. This avoids a full shuffle join, significantly reducing query execution time and data processing cost.
Q13. Your pipeline needs to mask sensitive customer data like emails and phone numbers before loading into BigQuery. How would you handle this?
Apply data masking or tokenization inside the Dataflow transformation step before writing to BigQuery. Use Cloud Data Loss Prevention API to automatically detect and redact sensitive fields. This ensures compliance with data privacy regulations without manual field-by-field handling.
Q14. You need to load data from a third-party REST API into BigQuery daily. How would you automate this?
Write a Python Cloud Function to call the API and store the response in Cloud Storage. Schedule it using Cloud Scheduler. Trigger a BigQuery load job after the file lands. This creates a lightweight, serverless, and fully automated daily ingestion workflow.
Q15. Your Dataflow pipeline works in testing but fails in production with memory errors. What would you do?
Increase worker machine type in Dataflow job options. Check if any PTransform is collecting too much data in memory, such as large side inputs. Optimize by using BigQuery as an external lookup instead of loading large datasets into pipeline memory during execution.
Read More :- GCP DATA Engineer Training in Chennai
SQL and Python Coding Questions Asked in GCP Data Engineer Interviews

Q1. How do you find the second highest salary from an employee table in BigQuery SQL?
sql
SELECT MAX(salary)
FROM employees
WHERE salary < (SELECT MAX(salary) FROM employees);
Use a subquery to exclude the highest salary, then find the MAX of the remaining values.
Q2. How do you remove duplicate rows from a BigQuery table using SQL?
sql
CREATE OR REPLACE TABLE dataset.table AS
SELECT DISTINCT * FROM dataset.table;
Recreate the table using DISTINCT to eliminate all duplicate records cleanly.
Q3. How do you write a BigQuery SQL query to find the top 3 products per region by sales?
sql
SELECT * FROM (
SELECT region, product, sales,
RANK() OVER (PARTITION BY region ORDER BY sales DESC) as rnk
FROM sales_table)
WHERE rnk <= 3;
Q4. How do you load a CSV file from Cloud Storage into BigQuery using Python?
python
from google.cloud import bigquery
client = bigquery.Client()
job_config = bigquery.LoadJobConfig(
source_format=bigquery.SourceFormat.CSV,
skip_leading_rows=1, autodetect=True)
client.load_table_from_uri(
"gs://bucket/file.csv",
"project.dataset.table",
job_config=job_config).result()
Q5. How do you calculate a 7-day rolling average in BigQuery SQL?
sql
SELECT date, sales,
AVG(sales) OVER (
ORDER BY date
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW
) AS rolling_avg
FROM sales_table;
Window functions handle rolling calculations efficiently without self-joins.
Q6. How do you read data from a BigQuery table into a Pandas DataFrame using Python?
python
from google.cloud import bigquery
import pandas as pd
client = bigquery.Client()
query = "SELECT * FROM project.dataset.table"
df = client.query(query).to_dataframe()
print(df.head())
The .to_dataframe() method converts BigQuery results directly into pandas.
Q7. How do you find customers who made purchases in January but not in February using SQL?
sql
SELECT customer_id FROM orders
WHERE EXTRACT(MONTH FROM order_date) = 1
AND customer_id NOT IN (
SELECT customer_id FROM orders
WHERE EXTRACT(MONTH FROM order_date) = 2);
Q8. How do you publish a message to a Pub/Sub topic using Python?
python
from google.cloud import pubsub_v1
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(
"project-id", "topic-name")
message = b"Hello from Python"
future = publisher.publish(topic_path, message)
print(future.result())
Q9. How do you write a SQL query to calculate year-over-year revenue growth in BigQuery?
sql
SELECT year,revenue,
LAG(revenue) OVER (ORDER BY year) AS prev_year,
ROUND((revenue - LAG(revenue) OVER
(ORDER BY year)) /
LAG(revenue) OVER (ORDER BY year) * 100, 2)
AS yoy_growth
FROM revenue_table;
Q10. How do you handle missing or NULL values in a BigQuery SQL query?
sql
SELECT
COALESCE(email, 'not_provided') AS email,
IFNULL(age, 0) AS age,
IF(city IS NULL, 'unknown', city) AS city
FROM users;
Use COALESCE, IFNULL, or IF to replace NULLs with meaningful default values.
Q11. How do you write a Python script to read a JSON file and load it into BigQuery?
python
from google.cloud import bigquery
client = bigquery.Client()
job_config = bigquery.LoadJobConfig(
source_format=bigquery.SourceFormat.NEWLINE_DELIMITED_JSON,
autodetect=True)
client.load_table_from_uri(
"gs://bucket/file.json",
"project.dataset.table",
job_config=job_config).result()
Q12. How do you pivot rows into columns in BigQuery SQL?
sql
SELECT * FROM (
SELECT product, month, sales FROM sales_table)
PIVOT (SUM(sales)
FOR month IN ('Jan', 'Feb', 'Mar'));
BigQuery's native PIVOT operator simplifies row-to-column transformation without complex CASE statements.
Q13. How do you delete records older than 90 days from a BigQuery table using Python?
python
from google.cloud import bigquery
client = bigquery.Client()
query = """
DELETE FROM project.dataset.table
WHERE created_at < DATE_SUB(
CURRENT_DATE(), INTERVAL 90 DAY)
"""
client.query(query).result()
Q14. How do you find the percentage contribution of each product to total sales in BigQuery?
sql
SELECT product,sales,
ROUND(sales * 100.0 /
SUM(sales) OVER (), 2)
AS sales_percentage
FROM sales_table
ORDER BY sales_percentage DESC;
SUM() OVER() without PARTITION BY gives the grand total for percentage calculation.
Q15. How do you write a Python function to check if a BigQuery table exists before loading data?
python
from google.cloud import bigquery
from google.cloud.exceptions import NotFound
client = bigquery.Client()
def table_exists(table_id):
try:
client.get_table(table_id)
return True
except NotFound:
return False
Visit our Website for :- GCP Data Engineer Online Training in Hyderabad
System Design Interview Questions for GCP Data Engineer Roles
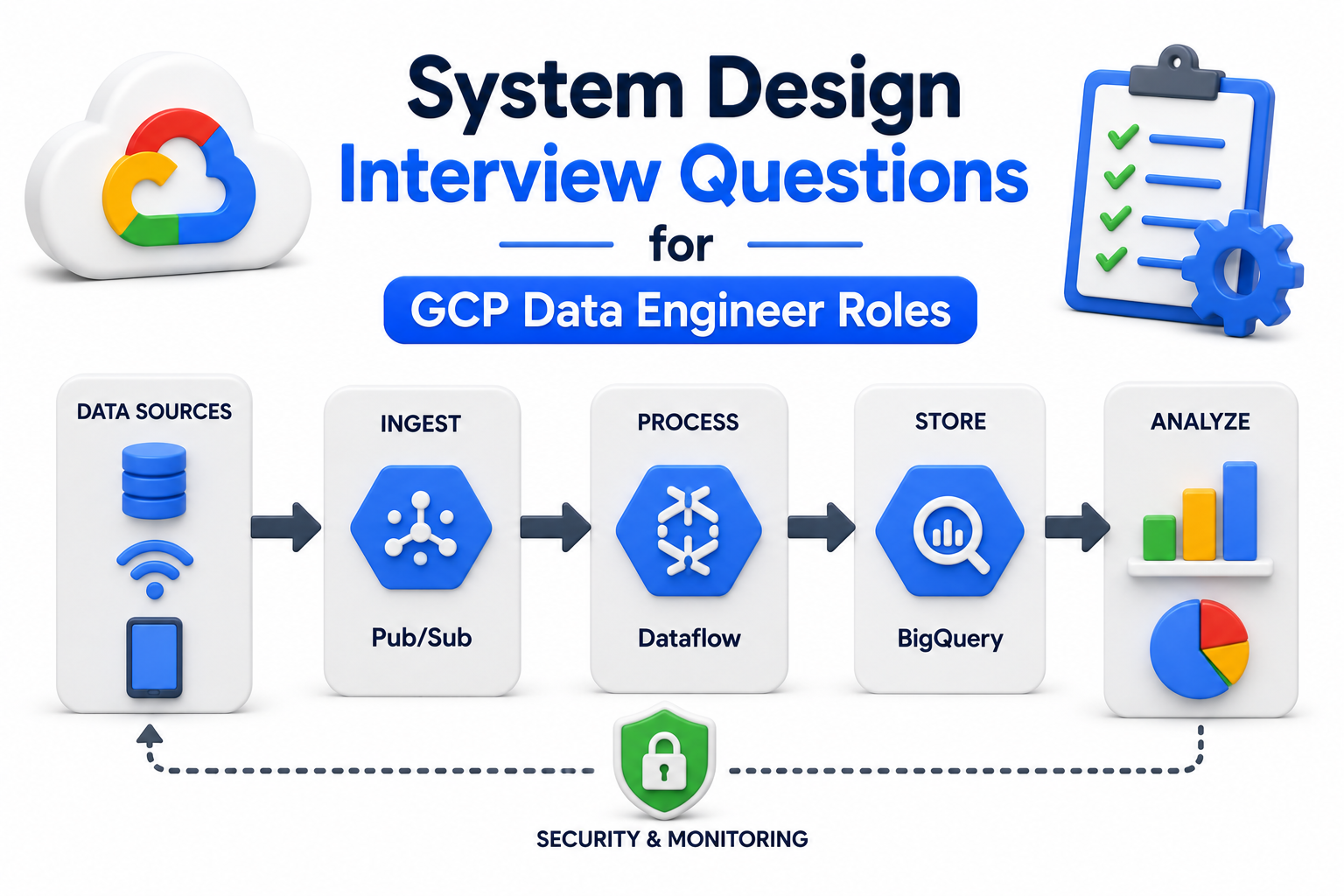
Q1. How would you design an end-to-end real-time data pipeline on GCP for an e-commerce platform?
Use Pub/Sub for event ingestion, Dataflow for stream processing, and BigQuery for storage. Partition BigQuery tables by date. Connect Looker Studio for dashboards. This handles high-volume real-time orders, clicks, and user activity efficiently at scale.
Q2. How would you design a data lake architecture on Google Cloud Platform?
Land raw data in Cloud Storage by zone — raw, processed, curated. Use Dataflow for transformation and BigQuery for analytics. Apply IAM roles per zone for access control. This layered approach keeps data organized, secure, and ready for multiple consumption patterns.
Q3. How would you build a scalable ETL pipeline that processes 10TB of data daily on GCP?
Use Cloud Storage as staging, Dataflow for distributed transformation, and BigQuery as the warehouse. Partition output tables by date. Schedule with Cloud Composer. This handles 10TB daily reliably without manual intervention or infrastructure management overhead.
Q4. How would you design a system to ingest data from 50 different REST APIs into BigQuery?
Write individual Cloud Functions per API, triggered by Cloud Scheduler daily. Store responses in Cloud Storage. Use a single Dataflow template to load all files into BigQuery. Centralize logging with Cloud Logging for monitoring all 50 ingestion jobs together.
Q5. How would you design a fault-tolerant streaming pipeline on GCP that guarantees no data loss?
Use Pub/Sub with message retention enabled. Build Dataflow pipeline with exactly-once processing semantics. Enable checkpointing for failure recovery. Store dead-letter messages in a separate Pub/Sub topic for reprocessing. This ensures zero data loss even during pipeline failures.
Q6. How would you architect a multi-region data pipeline on GCP for a global enterprise?
Deploy Pub/Sub and Dataflow in each region separately. Use multi-region BigQuery datasets for centralized analytics. Replicate Cloud Storage buckets across regions. This reduces latency for regional teams while maintaining a single source of truth for global reporting.
Q7. How would you design a cost-optimized BigQuery architecture for a startup with limited budget?
Use partitioned and clustered tables to minimize data scanned. Set slot reservations instead of on-demand pricing for predictable workloads. Archive cold data to Cloud Storage Coldline. Apply column-level security to avoid unnecessary data exposure and accidental full table scans.
Q8. How would you build a CDC pipeline from a MySQL database into BigQuery on GCP?
Use Datastream to capture change data from MySQL in real time. Stream changes through Pub/Sub into Dataflow for transformation. Write to BigQuery using merge logic to handle inserts, updates, and deletes. This keeps BigQuery always in sync with the source database.
Q9. How would you design a data pipeline that supports both batch and streaming using the same codebase?
Write the pipeline using Apache Beam's unified model in Python. Use bounded PCollections for batch and unbounded for streaming via Pub/Sub. Deploy on Dataflow for both modes. This eliminates maintaining two separate codebases for batch and real-time processing needs.
Q10. How would you handle schema evolution in a BigQuery pipeline when source data structure changes frequently?
Use Avro or Parquet with schema registry for structured evolution tracking. Enable BigQuery's schema auto-detection for new fields. Apply NULLABLE mode for new columns to avoid breaking existing queries. Version your schemas in Cloud Storage for rollback capability when needed.
Q11. How would you design a data quality monitoring system for GCP pipelines?
Add validation PTransforms inside Dataflow to check nulls, ranges, and formats. Route failed records to a Cloud Storage error bucket. Send alerts via Cloud Monitoring and Pub/Sub notifications. Log all quality metrics into BigQuery for trend analysis and daily quality reporting.
Q12. How would you architect a serverless data pipeline on GCP with zero infrastructure management?
Use Cloud Functions for ingestion triggers, Dataflow for processing, and BigQuery for storage. Orchestrate with Cloud Workflows for simple flows or Cloud Composer for complex ones. Every component auto-scales and requires no server provisioning, making it fully serverless end to end.
Q13. How would you design a pipeline to process IoT sensor data from 100,000 devices in real time?
Devices publish to Pub/Sub topics partitioned by device group. Dataflow aggregates and validates sensor readings using sliding windows. Write clean data to BigQuery and trigger Cloud Functions for threshold alerts. This architecture scales horizontally to handle millions of messages per second.
Q14. How would you build a data pipeline that feeds a machine learning model in production on GCP?
Use Dataflow to preprocess and feature-engineer raw data. Store features in Vertex AI Feature Store for reuse. Schedule retraining pipelines with Cloud Composer. Deploy models via Vertex AI endpoints. This creates a reliable, automated ML pipeline from raw data to production predictions.
Q15. How would you design a secure data pipeline on GCP that handles personally identifiable information?
Encrypt data at rest using Cloud KMS managed keys. Use Cloud DLP to detect and mask PII inside Dataflow before writing to BigQuery. Apply column-level security and row-level access policies in BigQuery. Log all data access using Cloud Audit Logs for full compliance visibility.